5·
2 months agoThe ladder was the first step on the way to civilisation.
The ladder was the first step on the way to civilisation.
BASIC DATA statement? Wow you were so lucky. On my ZX81 we had to enter them as characters in a REM statement that was the first line of code so we knew their address so that we could execute it. Address Space Layout Randomization? Couldn’t work on the ZX81!
That looked like machine code on a 8-bit micro, perhaps the Commodore 64 or VIC-20 (based on the screenshot and 40x20 text). So that would be the 6502. Child’s play compared to what you’d need to do on a modern chip.
You had 100% of my attention with the cat and mouse game.
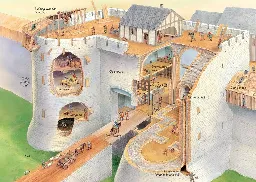
History is often much more interesting looking up from the average guy than looking down with all the majesty (and bureaucracy) of the nobles. This card has great insight into the common man.
You’re in luck!
Why would you carry an Axe over the should opposite the hand you’re holding it with?
That’s not an axe, it’s a bindle - exactly what a fool (in french, le fou) would carry.
What is up with his pants
He’s wearing medieval trousers - that is in fact two ‘hose’
These trousers, which we would today call tights but which were still called hose or sometimes joined hose at the time, emerged late in the fifteenth century and were conspicuous by their open crotch which was covered by an independently fastening front panel, the codpiece.
And again le fou is so stupid, his junk is out and all over the place.

Where else could the energy go?
It could be absorbed by the material and converted to either
In both cases the wearer is protected from uv, but the the spf will be found to be artificially low.

Many people do not hear as they read. In fact the skill of speed-reading depends on turning the auditory experience off:
There are three types of reading:
- Subvocalization: sounding out each word internally, as reading to oneself. This is the slowest form of reading.
- Auditory reading: hearing out the read words. This is a faster process.
- Visual reading: understanding the meaning of the word, rather than sounding or hearing. This is the fastest process.
Subvocalization readers (Mental readers) generally read at approximately 250 words per minute, auditory readers at approximately 450 words per minute and visual readers at approximately 700 words per minute. Proficient readers are able to read 280–350 wpm without compromising comprehension.
That’s 2376 barleycorns, or a small bag of grain if you will.
Or a barleycorn that’s one barleycorn long? Or a really large foot that’s a foot long. Or a chain that’s a chain long?

Danny Boyd wrote an excellent video essay on A Knight’s Tale. I too always wonder why there’s always someone cutting onions when I choose to watch.

Who’s the biggest dick. Sorry, I meant who has the biggest dick.

Remember the incident at the docks when the revolutionaries threw the T-Mobile imports into the harbour? Talk about high tariffs!

Don’t forget that train stations tend to be in the city centre while the airport is 30-60 minutes outside in a field somewhere, so travel time is much reduced.

I know the centrefold is a model, but what about the building?
Linux was not muscled like that in 1991 - it’s first, barebones kernel was released in September of that year.
I remember installing Linux on a 90MHz 486 in the mid 90s and it barely ran X server with a simple window manager. And if the machine was turned off while Linux was running, you might not be able to boot again.
Linux now, however, is unrecognizeably better.

Can’t be C, C is the true path.
Without him, America is a little greater again.

I’m guessing that exactly the same LLM model is used (somehow) on both sides - using different models or different weights would not work at all.
An LLM is (at core) an algorithm that takes a bunch of text as input and produces an output of a list of word/probabilities such that the sum of all probabilities adds to 1.0. You could place a wrapper on this that creates a list of words by probability. A specific word can be identified by the index in the list, i.e. first word, tenth word etc.
(Technically the system uses ‘tokens’ which represent either whole words or parts of words, but that’s not important here).
A document can be compressed by feeding in each word in turn, creating the list in the LLM, and searching for the new word in the list. If the LLM is good, the output will be a stream of small integers. If the LLM is a perfect predictor, the next word will always be the top of the list, i.e. a 1. A bad prediction will be a relatively large number in the thousands or millions.
Streams of small numbers are very well (even optimally) compressed using extant technology.



There’s another factor - days where thr earth is orbiting faster, eg on the closer side of the ellipse - are a different length midday to midday from when we are on the far side of the ellipse.
You can convince yourself of this when you consider that the area of the arc we traverse each day is the same (Kepler’s law). On the short side of our eliptical orbit, since the orbital distance is shorter, the arc must have a larger angle that we travel. That means the amount a point on the earth rotates to have the sun come back directly overhead must be different in different parts of the year.
This difference, summed day over day, results in a +/- 20 min movement of actual midday to 12pm. The ‘mean’ in Greenwich Mean Time refers to averaging this difference over the whole orbit.