I’m not familiar with koboldcpp, but i can see that you may have „Amount to Gen“ set very low. Try to increase it to a higher amount.
this post was submitted on 11 Sep 2023
8 points (100.0% liked)
LocalLLaMA
2237 readers
1 users here now
Community to discuss about LLaMA, the large language model created by Meta AI.
This is intended to be a replacement for r/LocalLLaMA on Reddit.
founded 1 year ago
MODERATORS
I would guess that this is possibly an issue due to the model being a "SuperHOT" model. This affects the way that the context is encoded and if the software that uses the model isn't set up correctly for it you will get issues such as repeated output or incoherent rambling with words that are only vaguely related to the topic.
Unfortunately I haven't used these models myself so I don't have any personal experience here but hopefully this is a starting point for your searches. Check out the contextsize and ropeconfig parameters. If you are using the wrong context size or scaling factor then you will get incorrect results.
It might help if you posted a screenshot of your model settings (the screenshot that you posted is of your sampler settings). I'm not sure if you configured this in the GUI or if the only model settings that you have are the command-line ones (which are all defaults and probably not correct for an 8k model).
Try MythoMax. I've had good results with that. For storytelling and all kinds of stuff. See if it's the model. I think some of the merges or super-somethings had issues or were difficult to pull off correctly.
also try the option --usemirostat 2 5.0 0.1
That overrides most options and automatically adjusts things. In your case it should mostly help rule out some possibilities of misconfiguration.
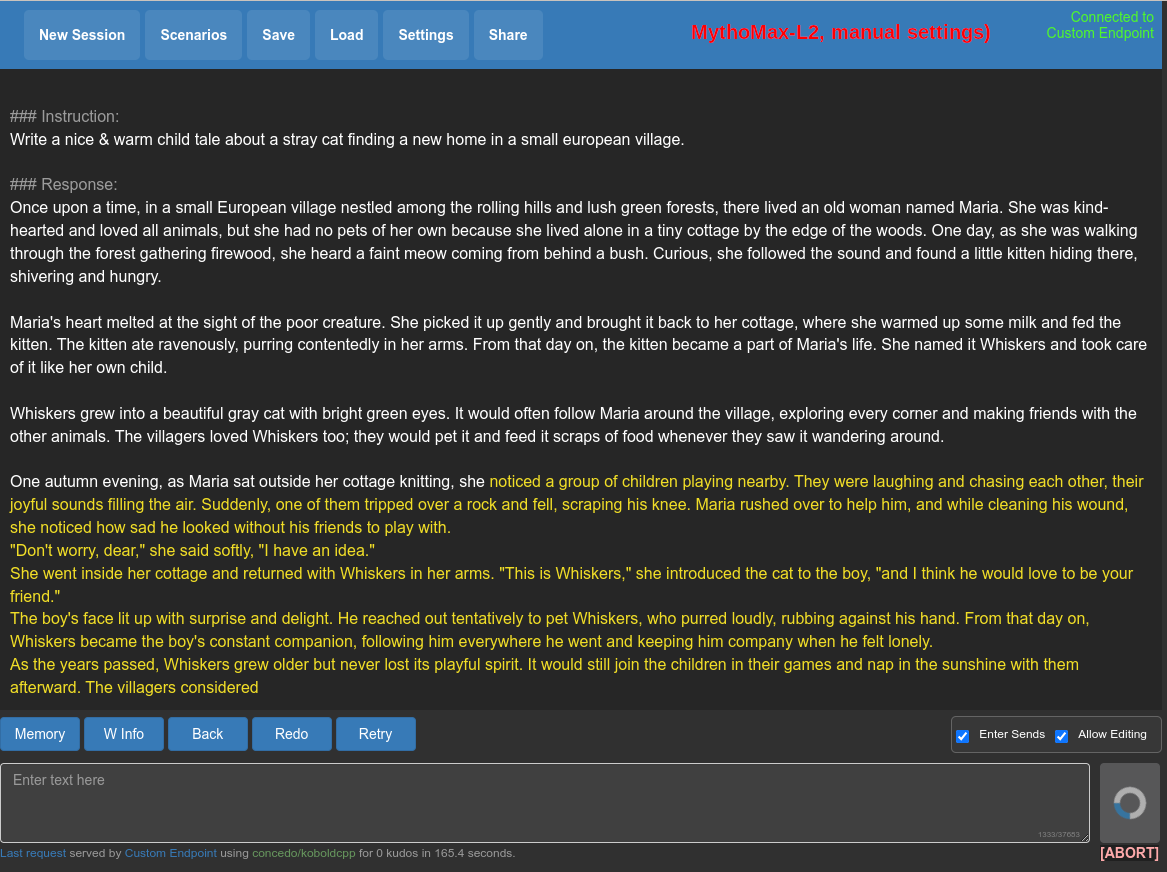
The MythoMax looks nice but I'm using it in story mode and it seems to have problems progressing once it's reached the max token, it appears stuck:
Generating (1 / 512 tokens)
(EOS token triggered!)
Time Taken - Processing:4.8s (9ms/T), Generation:0.0s (1ms/T), Total:4.8s (0.2T/s)
Output:
And then stops when I try to prompt it to continue the story.
That is correct behaviour. At some point it'll decide this is the text you requested and follow it up with an EOS token. You either need to suppress that token and force it to generate endlessly. (With your --unbantoken you activate that EOS token and this behaviour.) Or manually add something and hit 'generate again. For example just a line break after the text often does the trick for me.
I can take a screenshot tomorrow.
Edit: Also your rope config doesn't seem correct for a superHOT model. And your prompt from the screenshot isn't what I'd expect when dealing with a WizardLM model. I'll see if I can reproduce your issues and write a few more words tomorrow.
Edit2: Notes:
- I think SuperHOT means linear scale. So for a 8k LLaMA1:
--contextsize 8192 --ropeconfig 0.25 10000 - No
--unbantokensif you don't want it to stop - WizardLM prompt format is:
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.USER: Who are you? ASSISTANT: I am WizardLM....... - SuperCOT prompt format is:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\n\n\n### Input:\n\n\n### Response:\n - Storywrite is probably plain stories. But idk.
The chosen model is kind of badly documented. And a bit older. I'm not sure if it's the best choice.
Edit3: I've put this in better words and made another comment including screenshots and my workflow.
Yeah, I think you need to set the contextsize and ropeconfig. Documentation isn't completely clear and in some places sort of implies that it should be autodetected based on the model when using a recent version, but the first thing I would try is setting these explicitly as this definitely looks like an encoding issue.
I'll try that Model. However, your option doesn't work for me:
koboldcpp.py: error: argument model_param: not allowed with argument --model
What I'd advise you to do is something like this:
python3 koboldcpp.py --unbantokens --contextsize 8192 --stream models/mythomax-l2-13b.Q4_K_M.gguf
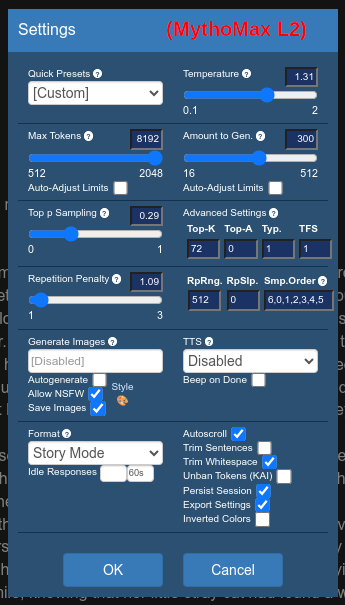
If you're unsure about your settings, just use mirostat:
python3 koboldcpp.py --unbantokens --contextsize 8192 --usemirostat 2 5.0 0.1 --stream models/mythomax-l2-13b.Q4_K_M.gguf
You can download MythoMax 13b ~~and there's an 33b~~. It's probably not 'the best' model out there, but I think a pretty solid one. It isn't super picky with the settings and does a variety of tasks well. [Edit: Watch out when using the 33b. I think it's broken. It generates lots of repetetive words for me.]
Notes: You probably need to add your --usecublas normal to that.
Fiddling with the contextsize comes with many caveats. Skip this parameter if you don't need it. Or learn how scaling works and which model needs which of the two methods with what kinds of numbers. Letting koboldcpp do the ropeconfig itself, makes it assume a few things that are probably wrong. You oftentimes have to set the 'ropeconfig' explicitly when doing any funny stuff. (Use a normal model and have it in gguf format. That's most likely to get the automatic configuration doing something sane.)
Regarding --unbantokens: You can delete that from your commandline and it will make the EOS token disappear, hence making the model unable to stop generating text. But, it'll also make it write an end to the story, following it up with "In the end ..." and then another "And together, they lived..." and then following it up with more and more repetitive stuff because the story is over yet you made it unable to stop.
With 'unbantokens' and once it won't continue on its own: Tick "Allow Editing", append a line break (or two) and hit 'Generate' again.
You can set the 'Amount to Generate' to something you like. You don't need to put in my value.
Getting your model to work: It is a LLaMA 1 based model. So it originally had 2048 tokens context. It is in the old ggml format, so koboldcpp probably doesn't know that. And judging by the name, I guess it was trained to have an 8k context with linear scaling. So I'd guess the following parameters are correct. And you absolutely need to specify it explicitly when using a model like this:
--contextsize 8192 --ropeconfig 0.25 10000
I don't have the time to fiddle with the parameters to get them right, so I just used mirostat. Feel free to instead try a few of the presets and play with the numbers. Maybe see if someone commented a good configuration for your favorite model somewhere.
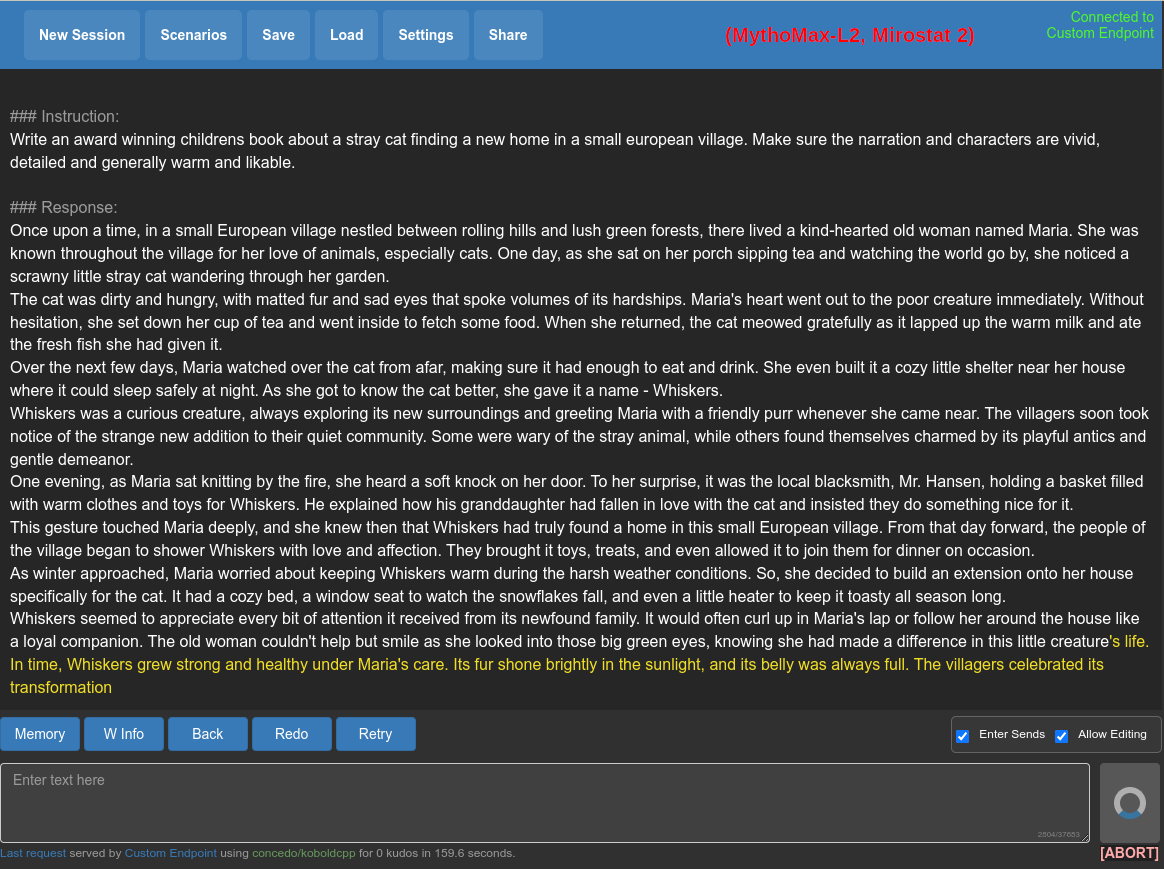
python3 koboldcpp.py --unbantokens --contextsize 8192 --ropeconfig 0.25 10000 --usemirostat 2 5.0 0.1 --stream models/WizardLM-Uncensored-SuperCOT-StoryTelling-30b-superhot-8k.ggmlv3.q4_1.bin
Regarding the prompt format: I'm not sure what a 'storywrite' model expects. You're giving it an instruction, but don't write it in any of the usual formats. That's most likely wrong in any case. If these models are trained with plain stories (which I don't know), you have to start with the story and let it autocomplete. You can't give it an instruction and hope for the best, it'll lead to subpar results. If you give it instructions, do it correctly. Find out the correct prompt format for that specific model.
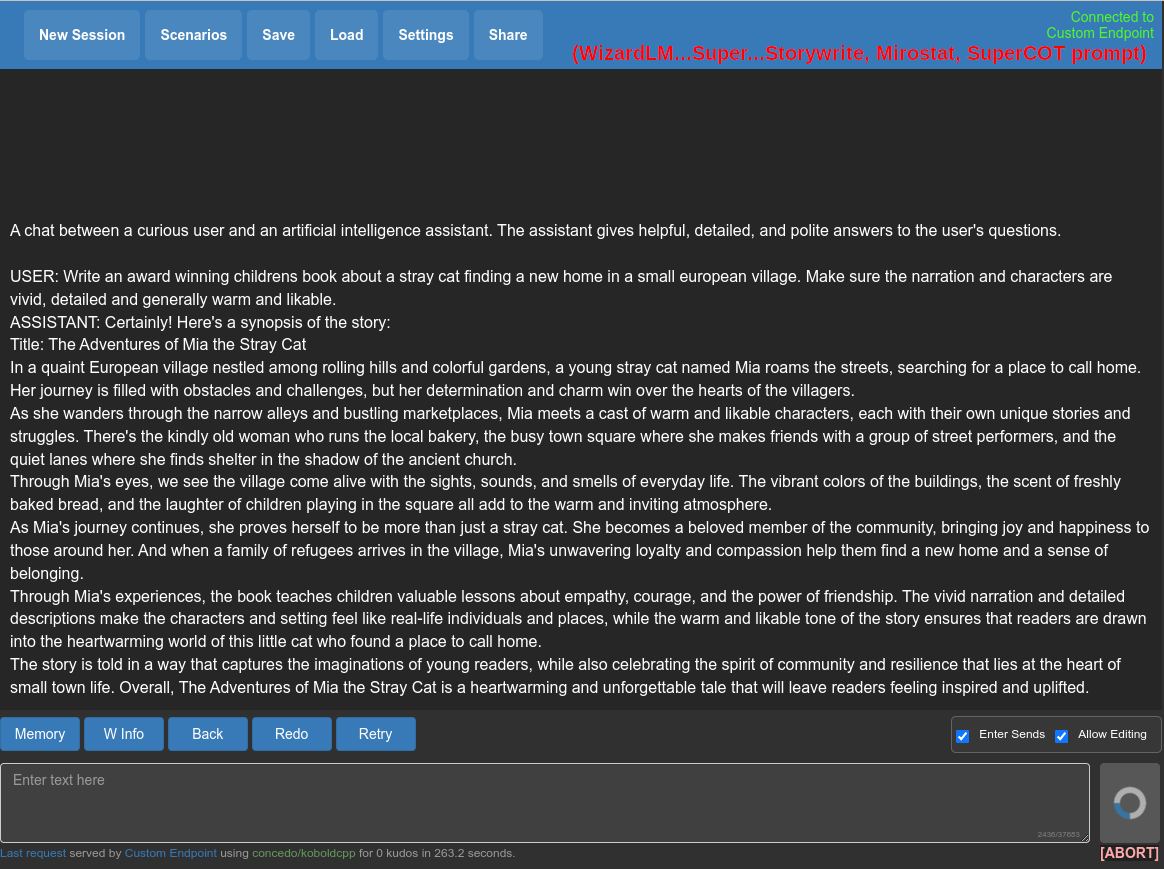
But maybe just don't use this model. These SuperHOT or 8k/16k/... models are from a time where we didn't have NTK-aware scaling yet. Nowadays you might just use the latter together with a 'normal' model. And as long as there isn't a reason against it, maybe use a model based on Llama2 which has twice the context to begin with (compared to the old LLaMA).
There are many other models like that out there. In fact there are many many models out there. And many of them aren't very good or are just obsolete. Don't pick one based on the fancy name. Choose one other people use. Rely on word of mouth. If it's good, other people will use it and maybe also talk about it, recommend good settings and how to prompt it. For popular models, you'll get that information on top.
https://huggingface.co/models?sort=modified&search=storywrite
Judging by the output you can see on my screenshots, the MythoMax writes way better stories anyways.
Here are some more prompt ideas:
### Instruction:
Write an award winning childrens book about a stray cat finding a new home in a small european village. Make sure the narration and characters are vivid, detailed and generally warm and likable.
### Response:
### Instruction:
You are the worlds greatet writer. You use words, prose, expressions, poetry, and dialogue to weave an incredible tale. Write in the style of book chapters. Write a fairy tale for children about a stray cat finding a new home in a small european village.
### Response:
Thanks a lot for your input. It's a lot to stomach but very descriptive which is what I need.
I run this Koboldcpp in a container.
What I ended up doing and which was semi-working is:
--model "/app/models/mythomax-l2-13b.ggmlv3.q5_0.bin" --port 80 --stream --unbantokens --threads 8 --contextsize 4096 --useclblas 0 0
In the Kobboldcpp UI, I set max response token to 512 and switched to an Instruction/response model and kept prompting with "continue the writing", with the MythoMax model.
But I'll be re-checking your way of doing it because the SuperCOT model seemed less streamlined and more qualitative in its story writing.
Alright. I have another remark: Add --ropeconfig 1.0 10000 after your --contextsize 4096.
You're not using a 'gguf' file but the ggml format that was used up until a few days ago. The older ggml format doesn't save any metadata with the model. That means KoboldCpp doesn't know what the original context size was. And doesn't know if it needs to scale to get to your specified 4096 tokens. I've read enough on the github page to know this fails. It'll assume a default context size of 2048 (which was the correct value for LLaMA1) and use scaling to get to the 4096 tokens. But that's wrong in this case, because in this case it's a Llama2 model and that already has 4096 tokens context size.
'--ropeconfig 1.0 10000' means 'don't scale' and that's the right thing in this case.
You can verify this by looking at the debug information KoboldCpp logs on startup. When I start it with your mentioned arguments, it says:
Using automatic RoPE scaling (scale:1.000, base:32000.0)
And that is about a 2x factor, which is wrong. I'm sorry this is so complicated, you basically need to know all that stuff. But that's the reason why we're changing the file format to 'gguf' which will make that easier in the future. Just add the 'ropeconfig' and you'll be fine for now.
If you want, you can learn more about 'scaling' here: https://github.com/LostRuins/koboldcpp/wiki#koboldcpp-general-usage-and-troubleshooting
Other than that: Have fun. I hope you get the technical details out of the way quickly so you can focus on the fun stuff. If you got any questions, feel free to ask. I always like to read what other people are up to. And their results (or interesting fails ;)
(I think 4096 is plenty for the first tries with this. If your stories get longer and you want 8192 context with a Llama2-based model like MythoMax-L2 use this: --contextsize 8192 --ropeconfig 1.0 32000 and don't forget to also adjust the slider in the Kobold Lite Web UI.)
Don't be sorry, you're being so helpful, thank you a lot.
I finally replicated your config:
localhost/koboldcpp:v1.43 --port 80 --threads 4 --contextsize 8192 --useclblas 0 0 --smartcontext --ropeconfig 1.0 32000 --stream "/app/models/mythomax-l2-kimiko-v2-13b.Q5_K_M.gguf"
And had satisfying results! The performance of LLaMA2 really is nice to have here as well.
Looks good to me.
For reference: I think i got the settings in my screenshot from Reddit. But they seem to have updated the post since. The current recommended settings have a temperature and some other settings that are closer to what I've seen in the default settings. I've tested those (new to me) settings and they also work for me. Maybe I also adapted the settings from here.
And I've linked a 33b MythoMax model in the previous post that's probably not working properly. I've edited that part and crossed it out. But you seem to use a 13b version anyways. That's good.
I've tried a few models today. I think another promising model for writing stories is Athena. For your information: I get inspiration from this list. But beware, that's for ERP, so erotic role play. So some models from that ranking are probably not safe for work (or for minors). But other benchmarks often test for factual knowledge and answering questions. And in my experience the models good at those things are not necessarily good at creative tasks. But that's more my belief. I don't know if it's actually true. And this ranking also isn't very scientific.
Ah thank you for the trove of information. What would be the best general knowledge model according to you?
Well, I'm not that up to date anymore. I think MythoMax 13b is pretty solid. Also for knowledge. But I can't be bothered anymore to read up on things twice weekly. That news is probably already 3 weeks old and there will be a (slightly) better one out there now. And it gets outperformed by pretty much every one of the big 70b models. But I can't run them on my hardware, so I wouldn't know.
This benchmark ranks them by several scientific tests. You can hide the 70b models and scarlett-33b seems to be a good contender. Or the older Platypus models directly below. But be cautious, sometimes these models look better on paper than they really are.
Also regarding 'knowledge': I don't know about your application. Just in case you're not aware of this... Language models hallucinate and regularly just make up stuff. Even expensive and big models will do this. The models we play with, even more so. Just be aware of it.
And lastly: There is another good community here on Lemmy: !fosai@lemmy.world You can find a few tutorials and more people there, too. And have a look at the 'About' section or stickied posts there. They linked more benchmarks and info.
Alright, thanks for the info & additional pointers.
I like to do my storywriting a bit differently, though. I had better results guiding it a bit more. Have a look at the following output. The process is as follows: I give it an instruction and let it generate the answer. Then I append the instruction for the next step underneath. During each step I obviously let it regenerate replies until I like the result and also generously edit things to my likings before resuming things.
The approach has several steps. I let it write a synopsis that I like. Let it come up with interesting main characters, the story arc, maybe a scenario. I split the actual writing into parts/acts/chapters. Doing it this way seems to generate better results than just instructing it to write something. Doing that results in a very basic arc of suspense (if at all) and random pacing of the story and characters enter and exit the stage at random. YMMV.
Remember, you can always let the LLM help you. Let it come up with 10 interesting titles for a book. Tell it to "Come up with some deep questions regarding ..." or challenging issues to face your main character with, that'll advance the story.
You can also give it extra instructions if you don't like the results. For example I sometimes write "Write chapter 1 ... of the story. Introduce the main character and set the atmosphere for the story". You'll have to do lots of trial and error. One thing: It'll pick up on the style of writing, the pacing and so on. So it'll get easier once you get past the first few paragraphs.
The following is only an example. The way I word things isn't necessarily the best choice. Also feel free to tell it to write a short story (these often result in several pages being generated) or a novel. Or a 5000 word story. You can word it like a school assignment or tell it to write in the style of Tolkien. (Regarding the 5000 words: LLMs can't count. It'll only give it a rough idea of something long or short. Don't expect it to do maths or give you something a precise length. But that is a frequent problem. Just make sure it roughly knows what you expect it to do.)
### Instruction:
Write a character card for private investigator cat. She is a female, anthropomorphic cat who recently moved to a small european village.
### Response:
Name: Private Investigator Cat
Species: Anthropomorphic Cat
Age: 28 (appears younger due to her feline agelessness)
Occupation: Private Investigator
Personality: Curious, observant, independent, and slightly aloof. Despite being new to the village, she maintains a professional demeanor in her work as a private investigator. She's quick-witted and resourceful when solving cases but can also be stubborn at times. Her feline nature sometimes shows through in her curiosity about small details and her tendency to groom herself compulsively during intense moments.
Appearance: A sleek black cat with striking green eyes, she stands at around 5'4" tall on her hind legs. Her tail swishes confidently behind her as she walks. She dresses professionally in a fitted suit jacket, slacks, and heels that accentuate her feline grace. A pair of cat-eye glasses perches on her nose, adding an air of intelligence to her appearance.
Background: Originally from a big city, Private Investigator Cat decided to move to this small European village for a change of pace and to escape the hustle and bustle of city life. She has a knack for solving mysteries and enjoys the slower pace of the village, which allows her to focus on her work without distractions. However, her unique appearance often raises eyebrows among the locals, making it challenging for her to blend in completely.
Skills: Excellent observation skills, sharp intellect, proficient in martial arts, fluent in multiple languages including French and German.
Case Files: Recently, she was hired by a local farmer to investigate strange occurrences on his property - livestock disappearing without a trace. Using her keen senses and knowledge of animal behavior, she discovered that a group of thieves were responsible for the thefts. Another case involved tracking down a missing heirloom necklace for a wealthy family in town. Her success rate is high, but some villagers still view her with suspicion due to her unconventional methods and appearance.
### Instruction:
Imagine a summary for a childrens book called "Detective Cat and the Case of the Stolen Necklace".
### Response:
Detective Cat, a clever and curious anthropomorphic feline detective, arrives in a quaint European village determined to solve mysteries. When a valuable family heirloom disappears, she springs into action using her sharp observation skills and feline agility to track down clues. With the help of new friends in the village, she uncovers a daring jewel thief's plan and retrieves the stolen treasure, proving that even in a place where everyone knows each other, crime doesn't pay. Will Detective Cat be able to solve more mysteries and earn the trust of the villagers? Find out in this exciting adventure!
### Instruction:
Write the table of contents for this children's book.
### Response:
Table of Contents:
1. Introduction to Detective Cat
2. The Mysterious Disappearance of the Heirloom Necklace
3. Gathering Clues and Making Connections
4. Following the Thief's Trail
5. A Daring Rescue Mission
6. Unmasking the Culprit
7. The Aftermath and New Beginnings
### Instruction:
Write chapter 1 of the story.
### Response:
Chapter 1: Introduction to Detective Cat
In a small European village nestled between rolling hills and picturesque vineyards, there lived an unusual character named Private Investigator Cat. She was not your typical resident; she stood tall at 5'4" on her hind legs and had striking green eyes that matched her sleek black fur. Despite being new to the area, she decided to set up shop as a private investigator after moving from the big city. The locals found her fascinating, but they also wondered what kind of trouble someone like her might bring to their peaceful community.
One day, Madame Dupont, a wealthy woman in town, approached Detective Cat with a peculiar request. Her family's priceless necklace had gone missing, and she wanted it back. The necklace held great sentimental value and was passed down through generations. It was made of precious gems and gold, making it irresistible to any thief. Detective Cat took on the case, eager to prove herself to the villagers. As she began her investigation, she knew that solving this mystery would be no easy feat.
[...]
(Generated with MythoMax-L2 13b (Q4_K_M), KoboldCPP on Linux. Settings are in the screenshot on the comment before. CLI arguments were in my case:
python3 koboldcpp.py --threads 2 --unbantokens --contextsize 8192 --ropeconfig 1.0 32000 --port 5001 --smartcontext --stream models/mythomax-l2-13b.Q4_K_M.gguf
Instructions are my words, everything after the ### Response: to the next instruction is what the LLM came up with. I haven't edited the output to move the story in any direction in this case. And I often just use the 'Story Mode', write all of the prompt myself and edit the text when doing things like this. You can set up Instruct Mode if you like.
I'm not an expert. There may be better ways to do it.