1
unRAID
0 readers
1 users here now
A community for unRAID users to discuss their projects.
founded 1 year ago
MODERATORS
2
3
The drives passes all SMART checks and has nothing flagging as a warning or fault, yet when I do a read test, I get all the errors.

4
5
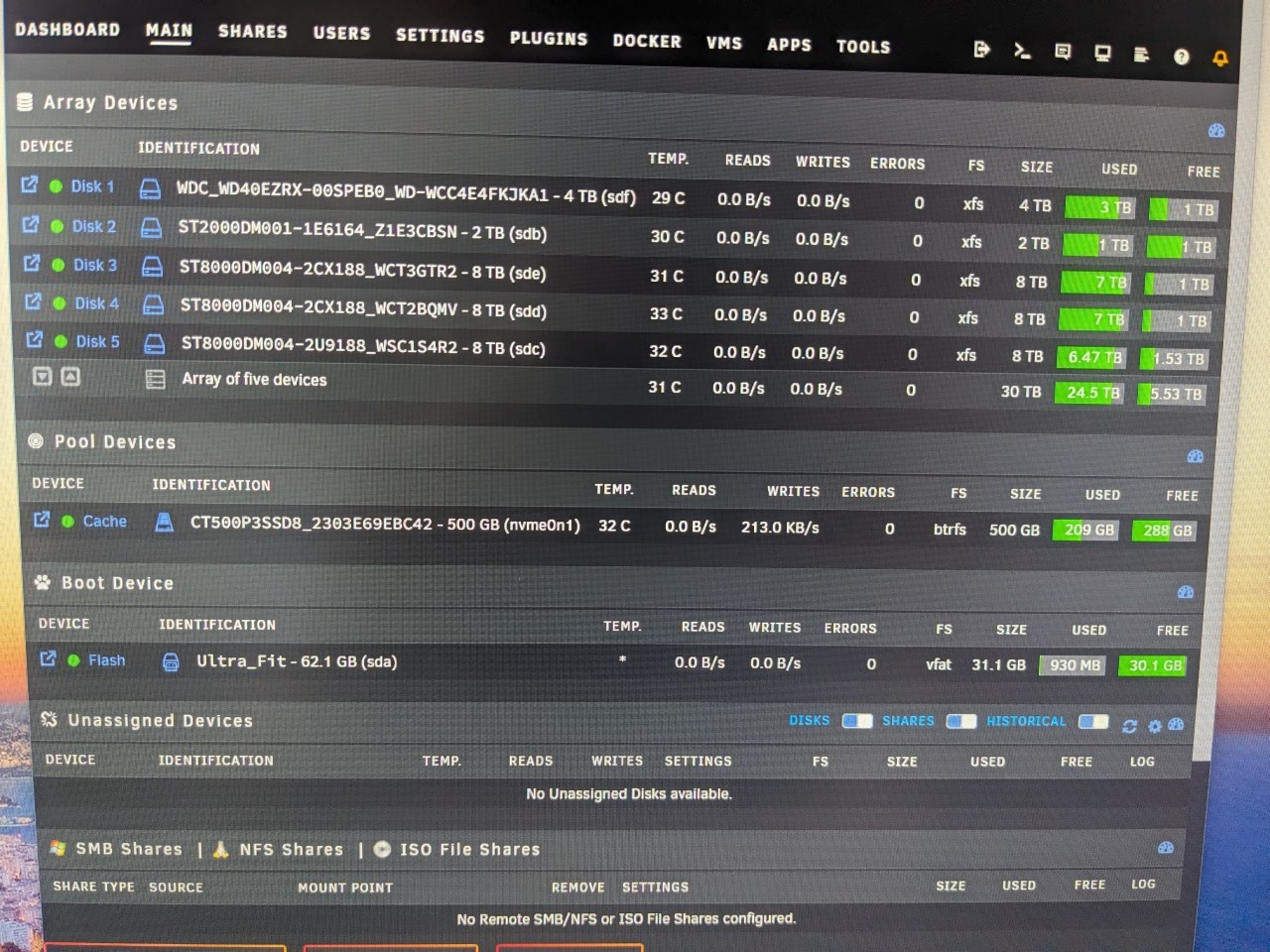
Appdata, isos, system and domains are the only things on the Cache drive, mover has been run and there is nothing on the cache drive that shouldn't be. I only have 1 docker installed currently (plex) and no VMs or ISOs downloaded or(no VMs). I have tried to delete old files that docker apps left behind, but some of the folders won't delete. ( I also have a share thsts empty but there are folders I can't delete (no files in them that I can see) and therfor can't remove the share)
I'm at a point where I want to restart my server from scratch, but don't want to loose the data on the drives in the array, can this be done? And if so, how?
6
7
8
9
10
11
So my SWAG docker can't see other containers on the same docker network, all the conf files need the IP and Port to work.
The other containers can see each other (sonarr and sab for example) and they are all on the same network.
Anyone know why?
Found the fix:

12
13
14
15
16
17
18
Hey,
I have a SSD pool with two relative small SSDs:

Now I started to notice that one of my SSDs started to fail. So I thought, why not use this opportunity to upgrade the pool. This is how I expect it to work:
- Buy two new bigger SSDs
- Restart server in safe mode
- Remove failing SSD
- Install one of the new SSDs
- Add the new SSD to the pool
- Start the Array?
- The pool should regenerate???
- Start with Step 3 again and replace the second small SSD
- Profit ???
Is this how it works or do I really first need to use the mover and move all data back to the hard drives and replace the pool all at once?
19
20
21

23
24
25
view more: next ›