

1·
3 months agoYes, it is fixed in the nightly builds and will be included in the next release.
Hungary 🇭🇺🇪🇺
Developer behind the Eternity for Lemmy android app.
@bazsalanszky@lemmy.ml is my old account, migrated to my own instance in 2023.
Yes, it is fixed in the nightly builds and will be included in the next release.
It will take some time, unfortunately. The build has failed for some reason. I’ve observed this in my pipeline as well. I am still investigating the issue.
I think this issue is fixed in this release.
Yes, it’s going to be updated very soon
Yes, I’ve released it as beta so that Google Play users can also try the new changes before the release. These builds are similar to the nightly, but I have to build them manually so they are updated less frequently.
I’m not sure what causes this issue. Does this happen when you click on a post, or does it happen when you are browsing for posts?
Also, what can you see on the web UI for these posts?

From what I’ve seen, it’s definitely worth quantizing. I’ve used llama 3 8B (fp16) and llama 3 70B (q2_XS). The 70B version was way better, even with this quantization and it fits perfectly in 24 GB of VRAM. There’s also this comparison showing the quantization option and their benchmark scores:
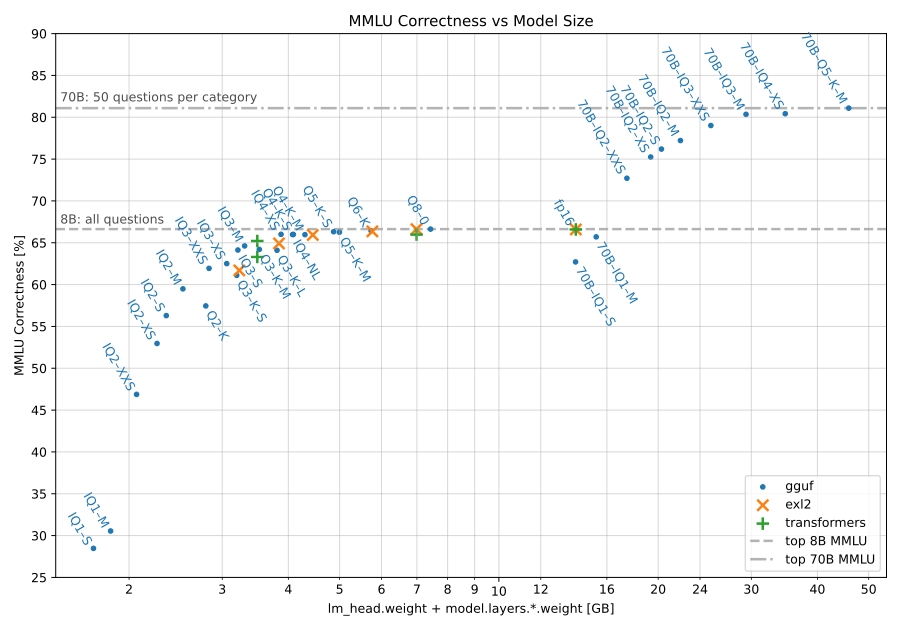
To run this particular model though, you would need about 45GB of RAM just for the q2_K quant according to Ollama. I think I could run this with my GPU and offload the rest of the layers to the CPU, but the performance wouldn’t be that great(e.g. less than 1 t/s).
Yes, you can find it here.
Are you using mistral 7B?
I also really like that model and their fine-tunes. If licensing is a concern, it’s definitely a great choice.
Mistral also has a new model, Mistral Nemo. I haven’t tried it myself, but I heard it’s quite good. It’s also licensed under Apache 2.0 as far as I know.

I haven’t tested it extensively, but open webui also has RAG functionality (chat with documents).
The UI it self is also kinda cool and it has other useful features like commands (for common prompts) and searching for stuff online (e.g. with searx). It works quite well with Ollama.
I have resolved this and other issues in the latest nightly build. I have also uploaded the fix to Google Play (it’s currently under review). If we do not encounter any further problems, I could release it soon.
I want to add kbin/mbin support in the future, but for now, Lemmy is my primary focus.
Thank you! I missed that. I will try to fix that too
Ahhh, your insurance is updated to Lemmy 0.19.5. The update will fix this issue.
Glad you’re sticking with Eternity! Could you let me know what’s broken on your side? I’d love to help you get it sorted.
Just wanted to add here that you can test the release early with the nightly builds or with the Google Play Beta program (it’s still under review, but hopefully it will be out there soon).
If you find any issues with it, please let me know so I can fix it before this release.
UPDATE: It should be available on the Google Play Beta now. Unfortunately, I’ve found some issues with posting comments/posts so I will need to fix that before the release.
Not yet, but I think I know what the problem is. I can probably fix it before this release.
Currently, there is no page to show you the list of communities (other than your subscriptions/blocks). However, I plan to implement something similar to this one soon.
I also want to add an instance view page that will show the list of communities for that specific instance as well.

Currently, I only have a free account there. I tried Hydroxide first, and I had no problem logging in. I was also able to fetch some emails. I will try hydroxide-push as well later.






I’ve also experienced it for a long time now. I’m not exactly sure what causes this, but I’ll try to look into it again.